
INTRODUCTION
How do your creations impact the lives of your audience? Your book inspires, your video educates and your song is shared and remixed through various mediums. The value you create is greater than dismal royalties and is not reflected in a simple page view counter. Use GretNet to track the holistic value of your creations and gain visibility into engagement and growth opportunities.
We challenged ourselves to build a practical system that could track and measure the value of every online interaction – a huge endeavor, albeit the future. The support we received from the Grant-for-the-Web program allowed us to build a proof-of-concept application with a future-proof design; Allow the measurement of the non-monetary valuations of creative web contributors.
Our mission of: transparency, accountability and attribution is a budding reality now that we have the foundations for evaluating real-world data in a consumable graph. While it's impossible to capture 100% of all worldly interactions -- GretNet provides the refineable methods and scalable infrastructure required to evaluate social pipelines.
Generate your own Creatives’ Report today (beta) or contact us for more details!
PROJECT UPDATE
We’re pleased to announce that our system has reach a point where it can automatically evaluate a Creators’ influence across different communities and publish a pdf report of the investigation. Our development-heavy project involved the design, development and integration of many technical modules.
Our current codebase consists of over 100,000 lines of Python code across a thousand custom source files. Roughly 30% of the effort was directly related to graph accounting algorithms, 10% in UX and the remainder focused on infrastructure and custom algorithms.
Our Lean design philosophy focused on generating a report that can be refined as needed. The core generation process takes about 10 minutes as the engine scours the internet and pulls data into its’ Neo4j graph database.
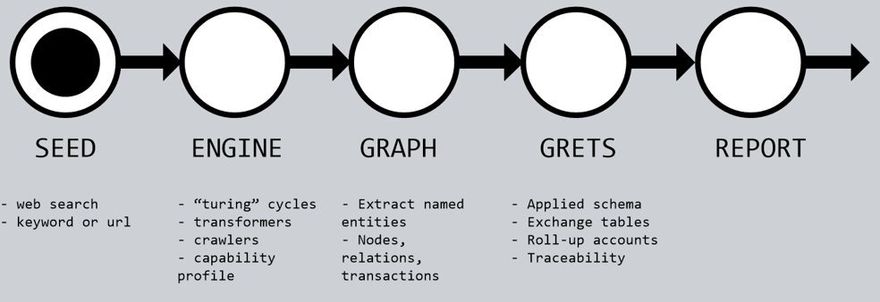
After applying a schema to track creations – the system starts an accounting process of quantifying value exchanged before rolling the details into a final report. The report includes the total Grets realized but, more importantly, the content was designed to be refined as: more types of data are added, value “exchange rates” are adjusted, and extra transforms are added. This due diligent design and refineable approach is key to the long term viability of the GretNet system.
PROGRESS ON OBJECTIVES
We reached our goal of building a software system that can track the non-monetary value of your creations (though generalizing for every source case is a long-term goal). The GretNet Creator’s pdf report details the activity surrounding your creative circle-of-influence and can be automatically generated across various publishing and social platforms.
To avoid the major pitfall of most software development projects we started by focusing on a core pipeline and the modules that directly support our novel Gret calculations. Once the base system was “live” we could return to add more data connectors and UX elements.
Our system is broken into three parts: (1) Storage Infrastructure, (2) Gret schema and (3) UX.
(1) Our infrastructure and storage system is online. We use a Neo4j hypergraph to capture a snapshot of the creative network under review. Most of the raw data is sourced via a custom search engine Yacy or generic connectors to services like Youtube.
(2) From a data perspective, we introduce a unit of a Gret at every edge in our Graph where value is exchanged. We use an extendible “exchange rate table” to help quantify creative value under different circumstances (ie/ value of a like from a bot vs human).
(3) We chose a lightweight web interface for supporting user queries and we also allow programmatic access via various API endpoint. The final report content and layout is supported by a Node based pdf templating engine and can be skinned or tailored as necessary.
Our setup is now positioned to pivot from core development to a longer term community adoption. For instance, we have an enterprise API endpoint for collecting Interledger transactions. Our integrated search engine periodically crawls the network of Coil blogs and our creatives’ target list has grown substantially to include contributors from Mozfest and beyond.
KEY ACTIVITIES
Our initiative focused mainly on the software development life-cycle (hence this rather technical overview of our system). It was driven by weekly Sprints and prioritizes reuseability via full test coverage. Our monthly priorities included the following items which, as a whole, form the processing engine:
(1) Base infrastructure including: database (Neo4j requires low-level interfaces for querying, inserts, walks, deletes and the plethora of Cypher algorithm queries), server hardware and base design schema (for creative entities and engagement types).
(2) Software architecture and core system modules: Yacy data indexing, NLP entity extractors, SVM machine learning models for classification of ie/ A Creation vs A Creator, a main queuing and execution pipeline.
(3) Basic web UI and pdf templating language. We kept the PDF formatting and generation process separate since it’s more complex then imagined and we want the ability to “skin” different formats. Our backend system runs via Amazon EC2 and routes to our main server for the heavy lifting requests.
(4) API interfaces for: Internal systems, normal use and future Enterprise extensions. For example, we can collect and index Hyperledger metadata. We also refined the Gret accounting algorithm at this stage.
(5) System integration such that the engine can run automatically from a simple input to a final report (we chose this approach over having Creators specifically filling out their profile). Our lightweight web interface talks to the backend via an internal API so exposing more features is rather straight forward.
(6) Our codebase is an entire application suite rather than a specific library (though it does use standard git repository version control). As a software package, it leverages Docker containers, 3rd party APIs, multiple DBs (SQLite, MySql, Neo4j), etc. The architecture is divided into a core system and a peripheral plugin/API system which does most of the interfacing. Our enterprise API interface is open source and contains integrated documentation using the Swagger standard. In addition to internal code comments, we have a draft technical architectural review document that gives a more thorough look at the various sub-modules.
We maintain stability via a main test entry point that includes unittests for the major systems and provides some basic functional testing validation. This test-first approach supports new installations but that’s only required if the user intends to index confidential documents or custom knowledge bases.
COMMUNICATIONS AND MARKETING
Our target user group is not click-bait-influencers but Creators and artists who value their contributions to society. We’ve been selectively compiling creator profiles from the local Mozilla ecosystem (as apparent when using our main keyword search tool). This includes interested parties from Mozfest, Mozilla pulse profiles, registered Coil blogs and those who registered on our original landingpage via Mailchimp subscriptions. If you think we’ve missed you – please reach out!
We have specifically avoided overhyping our project until we’ve quality checked its’ content across a few different communities. We’ve positioned to engage with our early adopters on a one-on-one basis. Our onboarding package has been storyboarded including partial video introductions and tutorials. To support further community discussions we encourage custom case code to be checked-in to our showcase/ repository. This is also the location where future 3rd party guerrilla audits of creators will be housed.
To support the developers we’ve compiled a draft whitepaper that gives an overview of the technical architecture of the system. It’s a work-in-progress document that will evolve as a more verbose explanation is needed in the various sub-systems. It’s also a good place to start for understanding the standard report execution process.
Our initial surveys where directed via our initial landing page into unique Google spreadsheets. This encouraged users to start their profile and report while filling in a short survey. While most seemed excited about what the report could offer -- they were anxious that they couldn’t immediately browse existing creator reports. One of the biggest insights was a need for – not only a search index for Creators and Creations – but a managed system for indexing reports and their administration.
WHAT’S NEXT
We’ve managed to come full circle on our development of a stand-alone package. As we move to the planned productization phase, we realize the huge opportunity in producing investigative reports that are based on a larger more complete breadth of data. In fact, as obvious in the other G4W projects, there are many new platforms and local creators who would benefit from a network evaluation. Therefore, one immediate plan is to offer our services in-kind to any interested Mozilla community member. This will let us fine-tune our backend while preparing it for the general use-case (and long term profitability). Another firm goal is to launch a report subscription service by the end of the year (2021).
What community support would benefit your project?
- If you’re currently publishing to an active community – reach out and we’ll freely evaluate your opportunities.
- While we had luck storing the Interledger protocol meta data we haven’t fully profiled it due to concerns over security (we’re currently keeping it separate from general use data) and we’re still working on its’ exchange rate entries (that maps the non-monetary factors). We plan to reach out again to the core Interledger team to see if there are extra fields available for storing more environmental states of each transaction. If this further Interledger feature interests anyone else -- lets' discuss.
Looking forward to further growth!

Top comments (0)