I resumed working on Little Webby Press today after taking an extended pause for the holidays and some peace of mind.
Some aspects of building an static generator seem simple at first glance, but are actually quite complex. A good example is generating a Table of Contents for a book. Upon a cursory inspection, one might assume that since each chapter is a markdown file, that just looping through all files and assembling an array is enough. Trouble happens when you stop to think a bit deeper about this problem.
Authors have their own ideas about what constitutes a chapter, and what should be included in a Table of Contents. In the sample book being used – Moby Dick – the author of the markdown files used a combination of <h3>for a hat and <h1>for the chapter title. Meaning that to assemble a working label for the Table of Contents, LWP needs to find the first <h3>in the HTML and then look for the <h1> that immediately follows it. Once LWP has all this information, it can render a nice Table of Contents that looks like:

This is how a chapter source looks:
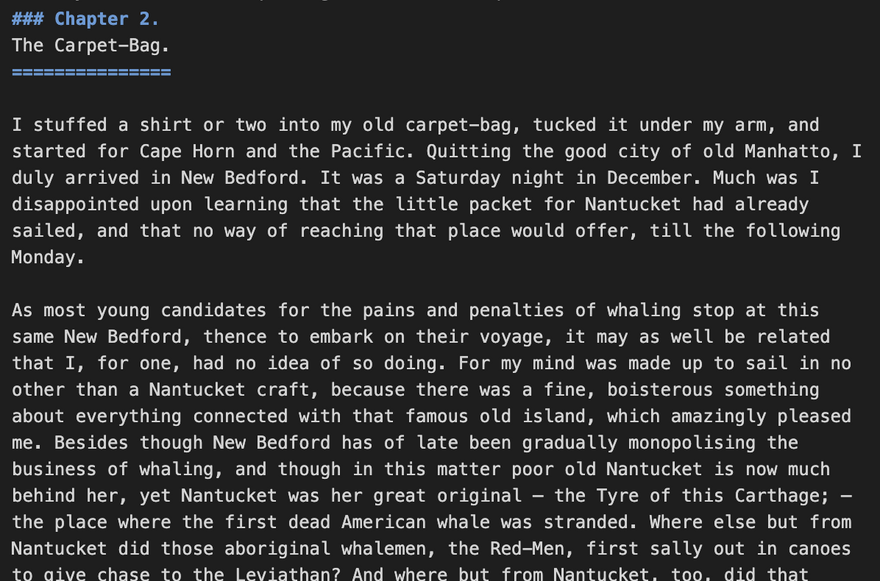
As you can verify, there is a small heading level 3 followed by a heading level 1 to mark the chapter header. The configuration for that book had to take that into account:
[toc]
prefix = "h3"
label = "h1"
match = "first"
The problem is that each book is its own island and other authors will want a different behavior. Some will want LWP to find multiple ToC entries per chapter. This is common for non-fiction, specially for programming books. Others will not use a little hat or prefix before the entry label.
To accomodate the most common use cases, I had to do a major overhaul of the Table of Contents routines and templates. I'm happy that the sample is being generated with the correct ToC, but there is still work to be done before I am able to start implementing the site generation and web monetization.
In my own subjective opinion, generating the website and WebMo stuff will be much easier than actually generating a valid EPUB3 file.
In another news, Amazon changed their approach to digital publishing and is now telling authors to upload EPUB3 files instead of MOBI files.
This is a major change since Amazon used to require a MOBI file while all the other players required an EPUB. This is because in the early days Amazon bought mobipocket who created the MOBI format for ebooks on Palm Devices IIRC. They were the only vendor requiring the outdated MOBI format. Kindle devices still don't know how to render EPUB files though, what happens is that Amazon KDP (their digital publishing service) will convert from EPUB to MOBI on their backend. If you still want to ship files to be sideloaded on a Kindle, you still need to generate a MOBI.
For me this signals they moving away from MOBI and maybe implementing EPUB renderers in the future devices. Because of this change, I'm changing the requirement of LWP to generate MOBI to a very low priority. MOBIs are only useful for sideloading now, and it is very hard to implement a whole new binary file generation format. Specially since Amazon MOBI spec is terribly undocumented.
Side-note: Amazon ships a desktop app that can convert EPUB to MOBI. This app should work well with EPUB files generated by LWP. This moves implementing MOBI on LWP to even lower priority.
Regarding WebMo, I think I'll have to opt to a naive approach to unlock chapters for monetized users. The generated site will be static, so there is no backend to protect hide content from the user. I'll rely on client-side JS (which is inspectable) to switch which chapters they show based on presence of WebMo. As long as I explain to the author that enterprising users will be able to find the unlockable content anyway, I think I'm OK.
My plan is to frame this as unlocking extra goodies and fun stuff. Things that there would cause no harm to the author if exposed to non WebMo readers.
I still need to do some work before being able to touch this anyway, anyone has feedback or comments?

Top comments (4)
I was thinking of doing similar for Audiotarky.com, but decided that it wasn’t suitable for music, so wrote a simple server to protect the content. I’m also wondering about a next step with some kind of drm, though maybe that’s over kill for CC licensed stuff (which is the MVP).
I think you’re right that so long as you’re clear about what can be done you are ok.
I think it all depends on your objectives and constraints. I really don't want to write a server because of three reasons:
That is why static deployment is right for me. The user will be free to host the files in any solution they want. It also enables the generated site to be distributed outside the normal web with IPFS, Hyper, and similar protocols.
Yeah, makes sense :)
Sounds like a good plan.