Project Update
The official start date for this project was June 16th. Due to various members of the team taking holidays around Europe (myself included), we really didn't hit our stride until mid July. Now I'm glad to report that we're making good progress, although mid-December (our planned launch date) looks very close indeed.
Although it's an ambitious task to create a product in 6 months – what makes it feasible is that we've built some of the key components before. It's hard to believe but The Hyperaudio Project (as a concept at least) is 10 years old this month! 🎉 🍰
Technology does not stand still – the web has changed significantly since those early demos, and the technology we've used has changed to suit – which means we still have lots to do!
Progress on objectives
Planning and Organisation
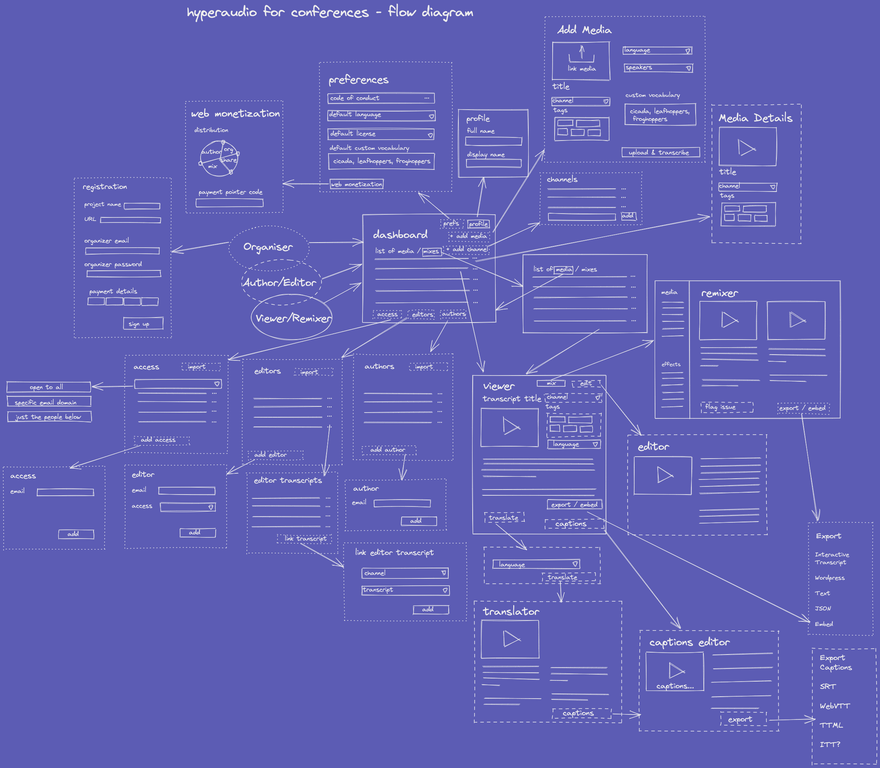
We continue to refine the flow of the application from a high-level using Excalidraw.
We're committed to working in the open. Our GitHub repository is public, as is our Project Board.
Wordpress Plugin
 "Russian doll" by Peter Becker is licensed under CC BY 2.0
"Russian doll" by Peter Becker is licensed under CC BY 2.0
We're happy to announce the completion of the integration of Web Monetization into the Hyperaudio Lite library and Hyperaudio Wordpress Plugin.
Read more about it in this post Adding Web Monetization to the Hyperaudio Wordpress Plugin
Or watch the video below for the details of how to use.
Transcript Editor
In our original timeline we placed work on the Editor before that of the Remixer, since then we've shuffled priorities around a little.
We decided that since the Remixer was really at the heart of Hyperaudio and also by far the most complex component – we should work on that first.
That said, we have commenced work on the Editor – some experimentation around maintaining decent performance without having to resort to pagination. Initial results are looking promising.
The Remixer
The Remixer is really what makes Hyperaudio special. The ability to combine content from a number of sources to create new forms is intuitive and actually a lot of fun (as we found out when we took Hyperaudio into schools). It also gels really well with Creative Commons licenses.
This will be the fourth iteration of our Remixer (orginally called the Hyperaudio Pad) – the most recent we created for the Studs Terkel Radio Archive. The version for conferences will include new features such as slides integration. We also want to make sure it's super easy to establish the source and context of any remix and so we're baking that right in. Essentially all remixes will come with "view source"!
This is a screen grab from a product we're using called Storybook which allows us to try out components as they are being developed.
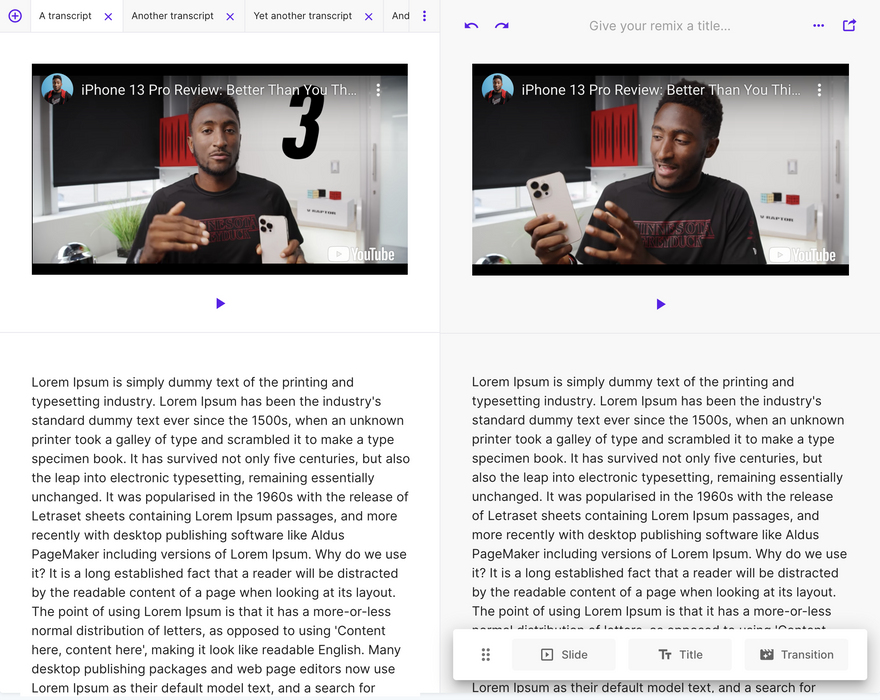
The Remixer in Edit mode and dual pane view
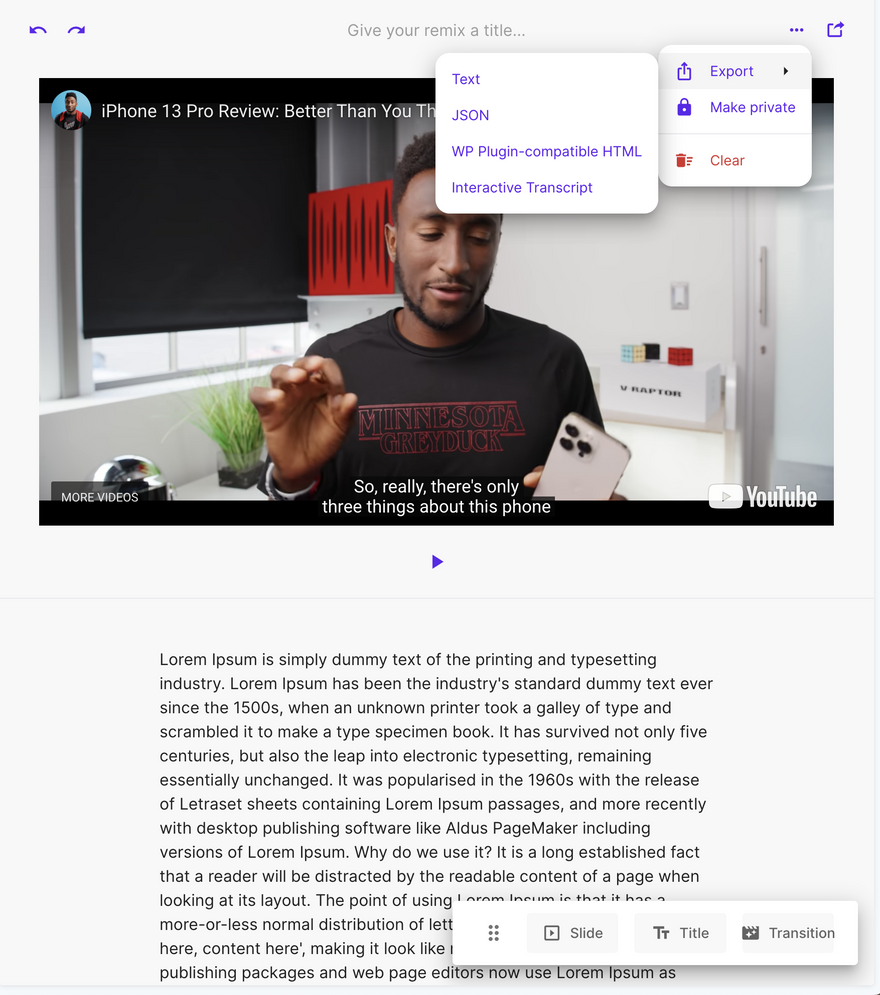
The Remixer in single pane view with export options
Backend Infrastructure
There's a lot going on under the surface of Hyperaudio. We need to be able to transcode, transcribe and translate media to provide the raw material (timed transcripts) upon which Hyperaudio is built. We'd also like this process to be efficient and as cheap as possible. To this end we use an architecture that has come to be known as "Serverless", which essentially means that once this architecture is in place we won't need to provision, scale and maintain servers. The tradeoff is that we need to build things within certain constraints.
The good news is that we're very close to having our serverless pipeline up and running.
And then we have role management. If you squint, you can see that in our flow diagram above we have three types of role:
- Organiser
- Author / Editor
- Viewer / Remixer
And we not only need to give differing permissions to each of these roles but also consider that the various pieces of media can have various permissions attached to them.
Branding and Landing Page
We had already established some branding for the new Hyperaudio family of products prior to running our pilot with Mozilla earlier this year.

Hyperaudio logomark & logotype

Hyperaudio larger logo idea

Hyperaudio smaller logo (and family) idea
As far as landing page content is concerned, we've been taking a look at what differentiates Hyperaudio from other similar platforms. It's been useful to establish our value propositions.
It's sometimes easier to understand what Hyperaudio is all about by seeing it in action, so we'll be combining our key value propositions with images, animations and videos on our landing page.
Also it's important to note that values should define tone. We talk more about our values under "Safety and Ethical Considerations".
Safety and Ethical Considerations
As a team and organisation we feel very strongly that we should could consider the various ways a platform can be abused and the implications for the users of that platform, before building it. (We'll write more about this soon as it merits its own post).
It's interesting to see newer companies that take advantage of AI starting to include an ethics page.
Pricing and Payment Plans
Nothing is set in stone yet, but we are considering keeping things simple and having annual plans. Most conferences occur annually and we hope that organisations will build upon each year's content when their new conferences come around.
We're also planning to team up with another GftW Grantee Permanent.org to offer plans where content can be streamed directly from a Permanent account and can be archived indefinitely, independent of having an active Hyperaudio for Conferences plan.
Plans will be based on hours of media and likely come in four sizes: 10 hour, 20 hour, 40 hour and 100 hour plans.
Discounts will be offered to non-profits, academic institutions and organisations working with underrepresented communities.
Routing and Subdomains
A quick note about routing and subdomains, which is a combined infrastructure and usability issue and something we decided while keeping an eye on having a family of products in the future. We have decided upon the following:
hyper.audio– top level domain where you find our family of products.hyper.audio/conferences– landing page for this particular product.mozfest.hyper.audio– example of subdomain for organisations signed up to any of our products.
Good news about our Twitter handle
We managed to get our Twitter handle changed from @hyperaud_io (which reflected our previous domain) to @hyperaudio. You should definitely follow us! 😊
Key activities
Our main GitHub repo resides at github.com/hyperaudio/hyperaudio
To play about with the latest versions of our components in Storybook – from the command line:
- Clone the
hyperaudio/hyperaudiorepo and switch todevelopbranch. - Change directory to
packages/remixerand runyarn - Change directory to then jump inside
packages/storybookrunyarnthenyarn start.
The Storybook page should pop up in your browser.
The Web Monetisable Hyperaudio Wordpress Plugin can be found at github.com/hyperaudio/wordpress-hyperaudio
The Web Monetisable Hyperaudio Lite Library can be found at
at github.com/hyperaudio/hyperaudio-lite
Happily we're starting to see Pull Requests come in from the general community.
Communications and marketing
Hyperaudio for Conferences and Grant for the Web (Blog Post)
Adding Web Monetization to the Hyperaudio Wordpress Plugin (Blog Post)
In other news, our "Get early access" list has grown to 122 people. We're also tweeting quite regularly from @hyperaudio
We are planning more marketing activities as we get closer to release.
What’s next?
We're aiming to complete the media pipeline and solidify the API in the next few weeks and in parallel start to breathe life into some key components such as the:
- Remixer
- Editor
- Translation Module
We'll also create some key mechanisms including:
- Caption Generator
- Rich Social Media Share and Integration
- Web Monetization Integration
We've still to design and implement all those pages that make up the rest of the platform, such as the Media Dashboard, Web Monetization allocation and permissions system.
We need to wrestle with GDPR compliance and integrate payment mechanisms.
We'll finalise the website identity, content and payment plans and hopefully sign Memorandums of Understanding with our potential partners (for now Permanent.org).
Wow – that's a lot. 😓
What community support would benefit your project?
We'd be interested in hearing from any conference organisers who would like to use the beta version of Hyperaudio Conferences. So if you know anybody who wants to make their conference material accessible and multilingual, please reach out to us and them 😄
We'd really like to know what you think about our project. We're always happy to receive feedback!
Contact us if you think there's a way to collaborate. If you'd like to couple any web-based audio or video with an Interactive Transcript, we'd be happy to advise and give you access to our work-in-progress editor.
Oh and please follow us on Twitter and give our GitHub Repos some stars! ⭐❤️
Additional comments
Just a big thank you to the Grant for the Web initiative, community and to the Hyperaudio team – Annabel, Dan, Joanna, Laurian and Piotr.
Relevant links/resources (optional)
In case they're useful to others, we can recommend:

Top comments (3)
10 years old! Wow - congrats to the entire team! It's wonderful to see how far Hyper Audio has come, and of course it's exciting to see WM integration in the Hyperaudio Lite library and WordPress plugin. Looking forward to seeing your continued progress and love the collab with Permanent!
@maboa This is exciting progress. Hyperaudio is an ambitious product and we're honored to be working with you on next steps leading up to your launch in December!
Likewise @omnignorant ❤️ what you're doing with permanent.org! December! OMG!