Project Update
Creating a completely new platform for conferences was always going to be a big lift – it certainly took more time and resource than we anticipated. That said, our team is really happy with the results.
It looks the part, works well and we feel that we're ready to take things to the next stage. There's a lot to report so apologies in advance for the length of this post ☕
A Quick Recap
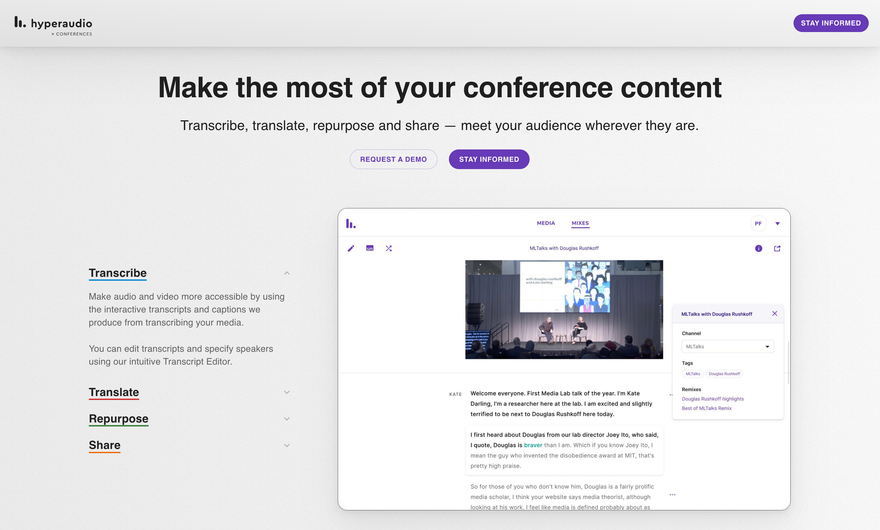
Hyperaudio for Conferences is a platform that aims to maximise the accessibility of conference content, while opening up new possibilities to repurpose that content.
We use machine generated transcripts and translations to increase accessibility, resulting in Interactive Transcripts and captions.
Although we're seeing huge improvements, the results of speech-to-text based algorithms are never entirely accurate and so we provide an intuitive editor to allow people to modify transcripts and translations.
Our transcripts are timed and we try to preserve those timings, even after editing.
Timings allow us to:
🌟 Highlight words as they are spoken (karaoke anybody?).
🌟 Navigate video by clicking on words.
🌟 Share snippets of text (with video attached!).
🌟 Repurpose by remixing using the text as a base and reference.
Partners and Allies
We partnered with a number of GftW grantees and sponsors:
The Permanent Legacy Foundation whose platform we're using as a media CDN giving us predictable video hosting costs.
New Media Rights who have been invaluable in providing legal advice related to media use.
MOVA who we liaised with to try out and and test the Hyperaudio Wordpress and JavaScript Libraries.
Creative Commons whose licenses we'll be using.
Mozilla Festival with whom we're currently piloting the latest version of Hyperaudio for Conferences with (see mozfest.hyper.audio).
Progress on Objectives
So let's take a look at the progress we made on our objectives.
Overarching goals
Our overarching goal was to provide a platform that allowed conference organisers to preserve, promote, repurpose and monetize their recorded content.
We saw Web Monetization as an opportunity to compensate existing content owners and incentivise the creation of new derivative forms of content.
Deliverables
In order to achieve all this we planned a number of deliverables.
Web Monetization
Our timed transcripts contain data pertaining to which user is currently speaking.
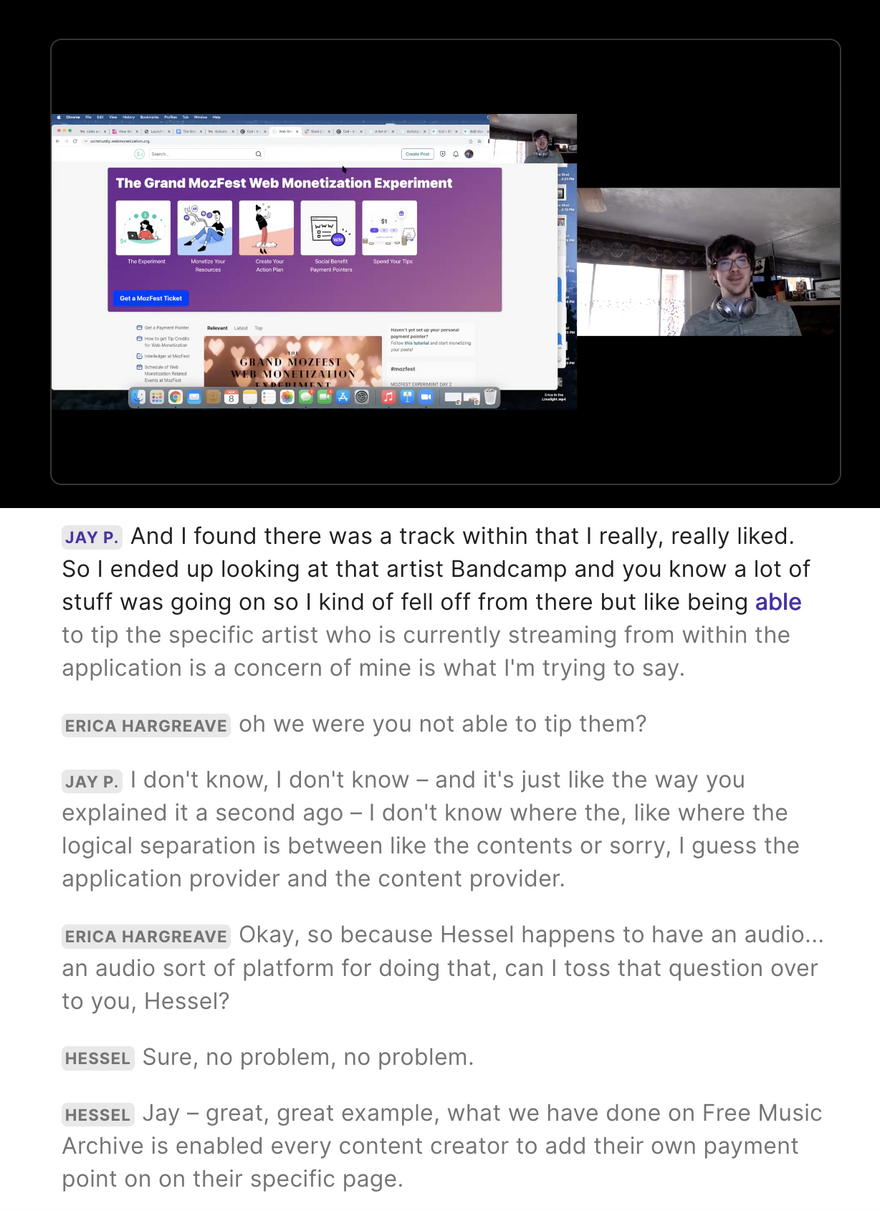
We can reference speaker data to know when to switch Payment Pointers, while people watch and interact with the video. The idea being that speakers will be compensated according to how much the part of the video they feature in, is viewed.
Once the transcript has been edited, conference organisers or editors can specify Payment Pointers for each speaker.
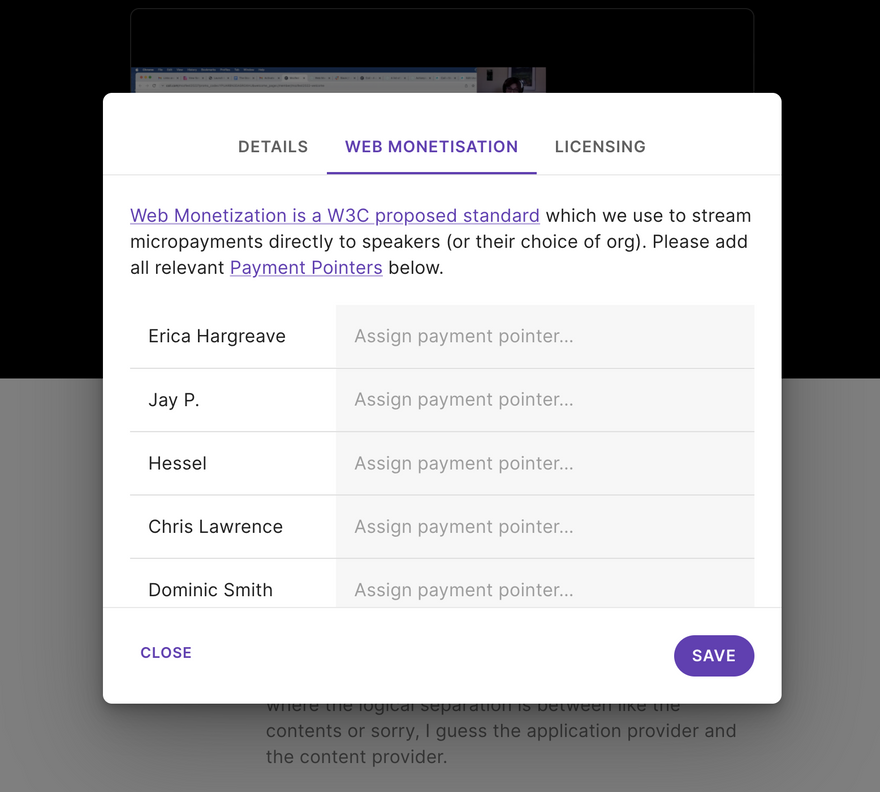
We have plans to take the Web Monetization aspect further by building in compensation for people who remix, share and edit content.
Transcript Viewer
One of the first parts of the system we built was the transcript viewer, this allowed us to test our API and make sure our representation of a timed transcript could be translated into an Interactive Transcript.
You can try out the Viewer by clicking on any of the following MozFest links:
🎈Activating Caribbean Digital Rights: Embracing Change in Digital Epistemology
🎈The Metaverse vs the Publicservice internet
🎈How to remote control a raspberry pi using web monetization
🎈Using Hyperaudio to increase accessibility of web-based audio and video
🎈Bright IDEAs: Embracing Inclusion, Diversity, Equity, and Access in a Post-Pandemic Environment
🎈With what words should I speak? Impact of Voice technology on Language Diversity
🎈The Grand MozFest Web Monetization Experiment - Getting Started
And here's an example of an edited translation:
Utilizzo di Hyperaudio per aumentare l'accessibilità di audio e video sul Web
Features we'd still like to add to the viewer include:
- Multilingual Captions (coming soon!)
- Select and share (coming soon!)
- Full Screen Video Mode
- Controls for altering Playback Rate
HLS
A quick footnote about our media format, we use the HLS format for video. This allows us more efficient "seeking" to playback points as well as the possibility to stream lower quality video as a low-bandwidth option.
Mobile
More people use mobile technologies to view web-based content than "desktop", for this reason we invested a lot of time making sure we can deliver a good viewing experience on mobile platforms.
Transcript Editor
When creating the Transcript Editor we had three main concerns:
It should be performant. It really needs to be fast to use, even almost imperceptible slowdowns in responsiveness can lead to a poor editing experience.
It should be easy and intuitive to use. Editing a transcript is a significant undertaking, we should make it as easy and enjoyable as possible.
It should maintain word timings. We adapted an algorithm created by the BBC to figure out word timings, no matter what you add or remove.
Speaker data is an important part of a transcript. We spent a fair bit of time getting the speaker input and selection to work the way we wanted it to.
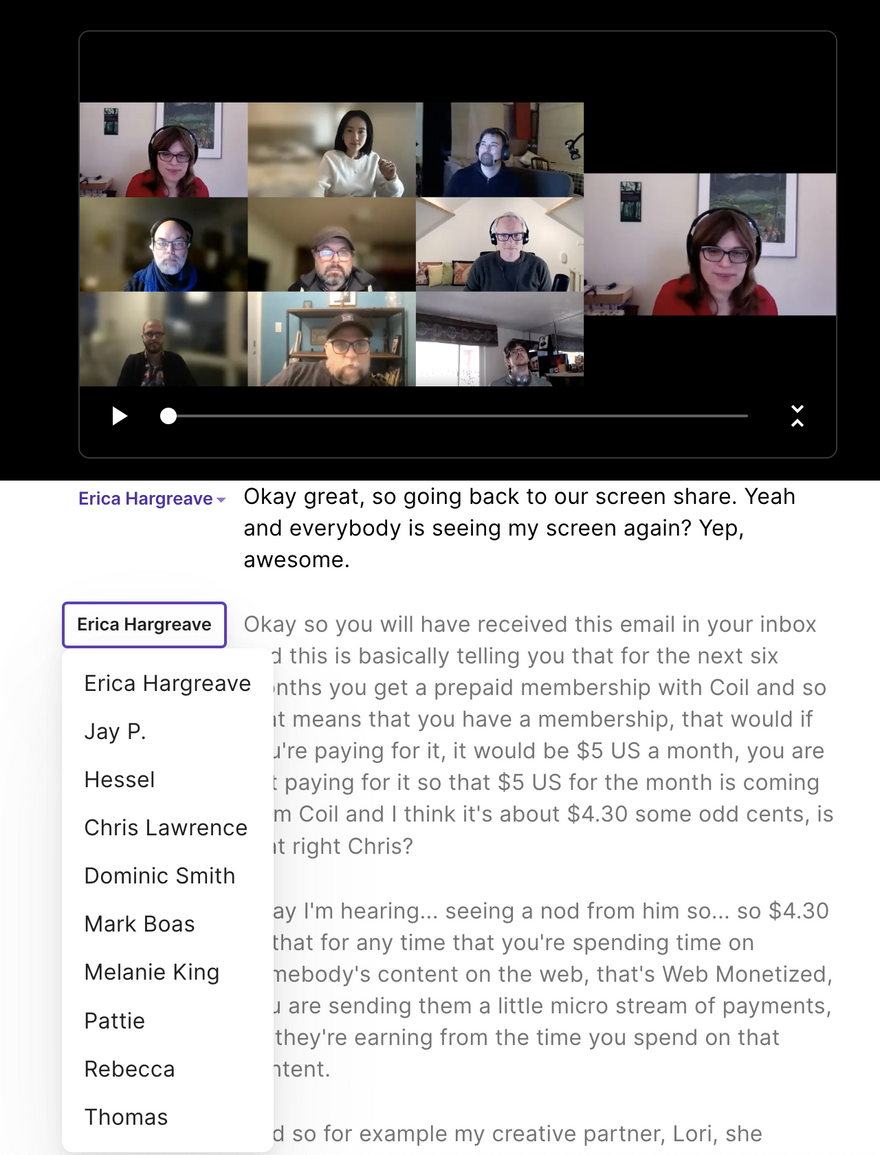
Since automatic speaker id (also known as diarisation) is a bit hit and miss, an optimisation we felt worth pursuing was the downloading of the automatic live transcription from Zoom. Fortunately Zoom provides captions and associated speaker data in a standard VTT format.
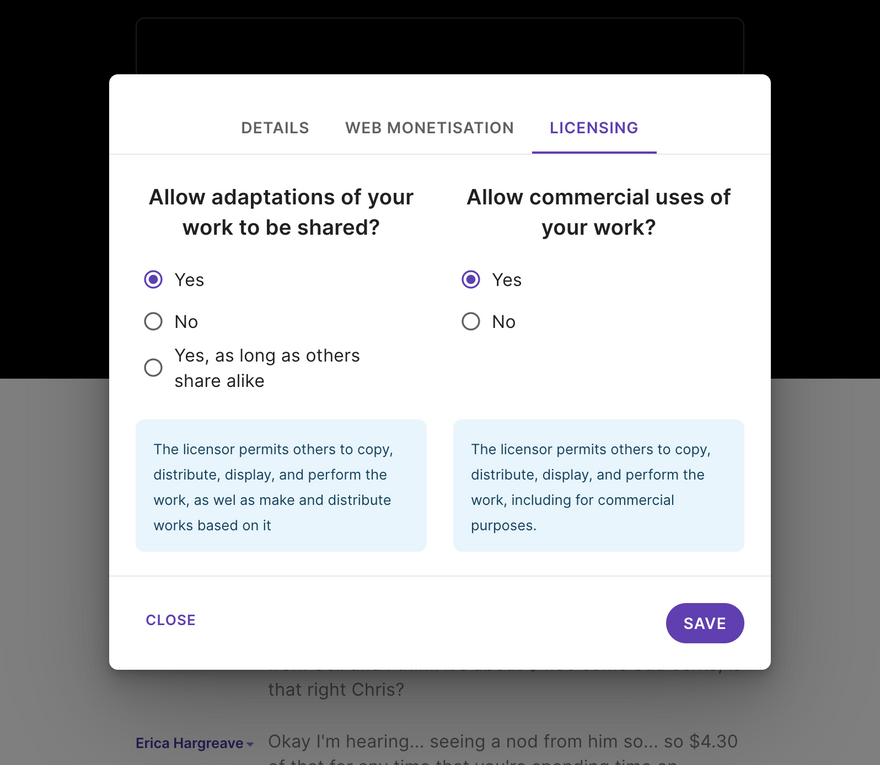
License Transparency
We're committed to making licensing as transparent as possible and to this end we've built a Creative Commons license selector, which the editor can utilise before publishing.
The Remixer
The Remixer holds a lot of promise for repurposing content. It allows people to construct new videos just by moving text around, and so it's a very intuitive content-based way to assemble new forms.
Making easy-to-use tools can be hard and the Remixer is the most complex part of the platform to build. At MozFest in March I demoed an early alpha version and I'm pleased to say that we are on the verge of having a fully functioning version ready for people to test.
I sometimes (half) joke that 90% of our development time was spent on The Remixer! But remixing and repurposing content is at the heart of our platform, so we're taking the time to make sure we get this part right.
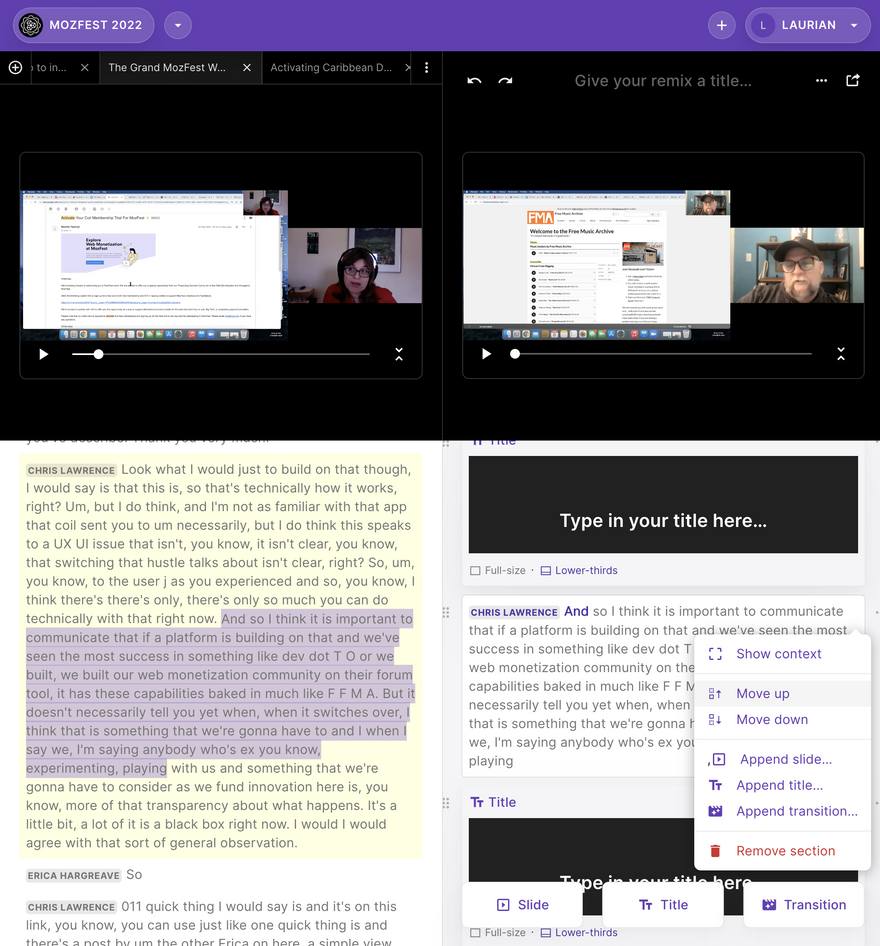
One of the great things about The Remixer is that it's an "on-the-fly" audio and video editor. That is to say that we're assembling the resultant mix as a type of playlist, where you can specify the start and stop times of items in that playlist simply by selecting text. No mixing down to a single file required.
Each item or snippet maintains a link to the larger piece of media it references, which means that not only can we present the context of any mix, but we can also allow remixes to be expanded as well as contracted.
It's useful to be able to remix conference material:
– It allows you to quickly make shorter and tighter versions of a talk.
- You are not restricted to one source either, you can create mixes from different sources based, say, on a common theme.
We also have plans to make search results a type of remix. Search for a phrase or term and see a remix made up of paragraphs where that phrase is mentioned. This could also act as a base for a new remix. Wow – so much remix! Did I mention remixes are remixable and that you can remix the remixes?😬
As remixes can be presented through the Viewer you can embed those remixes into any web page.
Wordpress Plugin and Hyperaudio Lite
We're keen on users of the Hyperaudio platform to be able to reuse their data in other contexts. We go further than embedding by providing two libraries which can be used with an HTML representation of timed-transcripts and a link to the video.
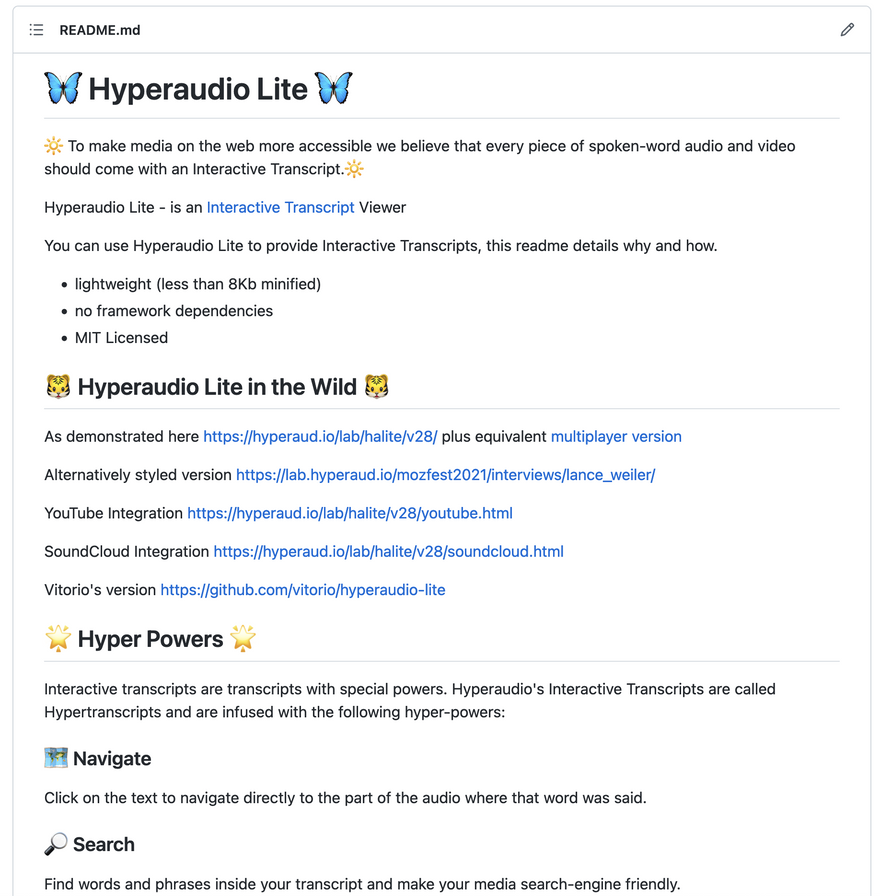
Hyperaudio Lite is a lightweight JavaScript library that allows developers to create and customise Interactive Transcripts, which in turn makes up the core of the Wordpress Plugin making it easy for non-developers to do the same.
These open source modules have been [extended to support Web Monetization] and slowly improved upon, with the help from the Hyperaudio community.
We plan to support remixes in Hyperaudio Lite and to generalise the caption generation module, so that it can be used independently from Hyperaudio Lite.
Ian Forrester who works for BBC R&D has been experimenting with Hyperaudio Lite to Web Monetize DJ mixes so the artists can be compensated, he's calling it WebMix.
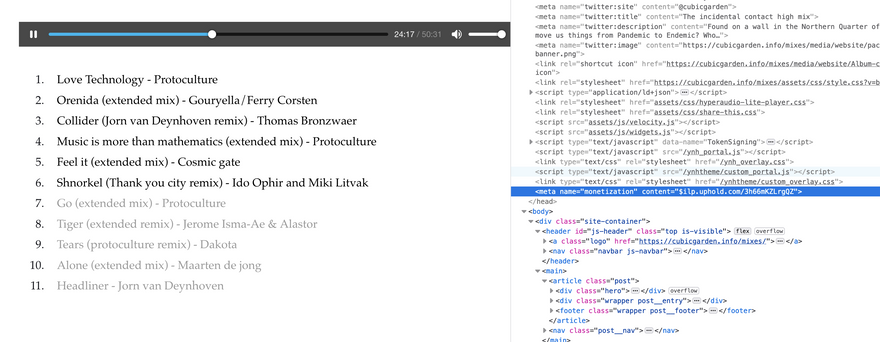
Check it out on his blog post – The incidental contact high mix.
Export, Embedding and Permanent Access
As part of our anti "lock-in" strategy we're committed not only to providing mechanisms to embed content from the Hyperaudio platform, but also more robustly to allow that content to be hosted and reused independently.Our collaboration with Permanent is important, because it means predictable video streaming costs. It's also makes a nice ad-free alternative to YouTube.
Since the data we produce includes both transcripts and media, we provide a way of exporting both representations, in coupled and de-couple forms. You can export as plain text, captions (in SRT and WebVTT formats) as well as video, audio or integrated media and transcripts.
Key activities
Community
An important key activity for us was the building up of community around Hyperaudio.
MozFest 2022
When we applied for funding we were not sure whether Hyperaudio for Conferences would be used and developed alongside Mozilla Festival – MozFest 2022.
I'm pleased to say that after a small and low-key pilot last year, the MozFest organisers were enthusiastic to experiment further with Hyperaudio this year and this has been invaluable in attracting an international community.
Although MozFest is an international festival, most of the content is in English, so there's a real appetite to translate content and it's great to be able to test out our internationalisation workflows with an international community.
Building a community is challenging, so it was a real benefit to have Mozilla's support, and to be able to contact the facilitators of all the amazing content that MozFest produces.
We ended up with 32 sessions to transcribe and translate. And some very enthusiastic facilitators who saw the potential for their content to reach a broader audience.
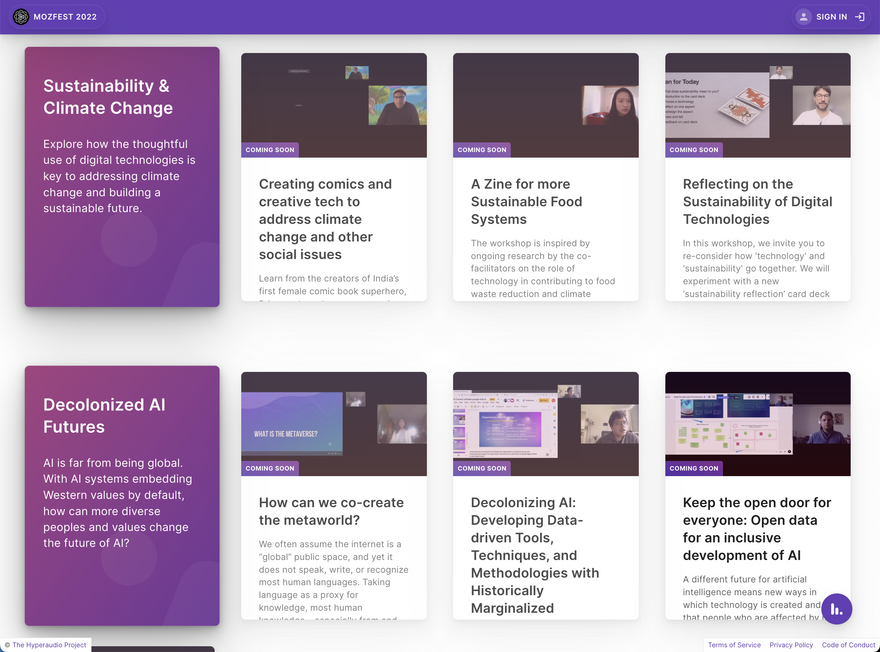
We also benefited from Interledger's support at the festival, becoming part of the Grand Web Monetization Experiment.
The work we're doing with the MozFest community is ongoing and we recently ran an "Editathon" so that we could meet each other facet-to-face while editing and translaing content as a group. We're planning more of these sessions which will culminate with a "Remixathon".
Ethical Aspects
Hyperaudio has a strong ethical position which we invested a fair bit of time in discussing and capturing. This position informs our design decisions and policies. As well as being an open source platform that encourages users to take control of their content (through the anti-lock-in features discussed earlier), we also want Hyperaudio for Conferences to be a safe space. We wrote a lot more about this in a separate post and many aspects are reflected in our Code of Conduct.
As we slowly roll out Hyperaudio, we want to be able to choose the conferences which we invite on to our platform. So one of the first things we put in place was a waiting list. I'm pleased to say that there are people on it!
Privacy
One important is that of privacy. With MozFest for example, we need to mirror their privacy policy, which means that after a certain period we need to take video content down, although we can give those videos to facilitators to use as they wish, as long as we mask participants' identity. Luckily we have the data to be able to do this automatically, the idea being to use the facilitator view and mute the audio, while providing captions. Also we advise using speaker names that don't reveal the speaker's identity.
Open Source
All our code is open source and available on GitHub. You'll also find issues and documentation there.
Communications and marketing
We have a newsletter with * checks notes * 182 readers, who we are keeping up to date with progress. Please join :)
We're also pleased to announce that we managed to change our old Twitter handle from @hyperaud_io to the much nicer @hyperaudio. Where we tweet from time to time. Please follow :)
We've blogged on webmonetization.org and I've blogged some more personal stuff on maboa.it.
During MozFest we put together the following resources as public Notion docs:
What’s next?
Phew! We've achieved a lot. The platform looks professional and slick and we have the main pieces in place which we were able to gain validation and feedback from the small community that we built.
We're ambitious and so we aimed high and we still have a bit more of the road to travel until we get to where we want to be. But we plan to build upon the momentum that we have, to add polish to the platform as we emerge from beta.
We also have plans to create a desktop application which will be able to submit content for inclusion in a new community area of Hyperaudio we hope to build.
What community support would benefit your project?
Community Activities
We'll continue to run Editathons, Translatathons and Remixathons for MozFest content. If you think you would be interested in participating, please contact me directly or join the #Hyperaudio channel in the MozFest Slack.
Conferences
It's been great to be able to liaise with Mozilla on MozFest, we want to keep the momentum going by working with other conferences.
If anybody knows of any other conferences that could benefit from Hyperaudio for Conferences, please point them towards our website, where we have a waiting list.
Further Funding
We aim to be a sustainable non-profit and so we'd love to hear about any further sources of funding so that we can move to the next stage.
It doesn't need to be confined to conferences, other applications of the technology include:
- Educational (especially in the areas of Media Literacy and combating Misinfo and Disinfo)
- Lecture Capture
- Podcasting
Additional comments
Just wanted to say thanks to Annabel, Joanna, Laurian and Pio for dedicating so many hours to this project and our collaborators – Soledad, Nic, Ian, Sophie, Sofia, Sebastian, Priscila, Hillary, Pamela, all our 32 registered users (woo!), The Permanent Legacy Foundation, The MozFest Team, Nathalie and Art of New Media Rights and of course the Interledger team for making all of this possible.
❤️❤️❤️
Relevant links/resources
Hyperaudio Website
Hyperaudio for Conferences
MozFest Hyperaudio
Hyperaudio on Twitter
Hyperaudio on GitHub

Top comments (2)
Hello,
I am annotating several articles from the community for better reach outside of the community.
Here is yours.